Generative Image Models
Generative image models are a family of algorithms and neural network architectures specialized for creating images from patterns learned during training, often with guidance from human language prompts. The most influential modern approach is the diffusion model. Imagine a sculptor who has spent years studying what thoughtful people look like: their posture, expressions, and subtle details. We blindfold the sculptor, hand over a random block of marble, and say, “Make me a sculpture of a person thinking.” The sculptor cannot add new material; instead, they feel the block and chip away small pieces that clearly do not belong. Repeating that process thousands of times gradually reveals a coherent form from within the noise.
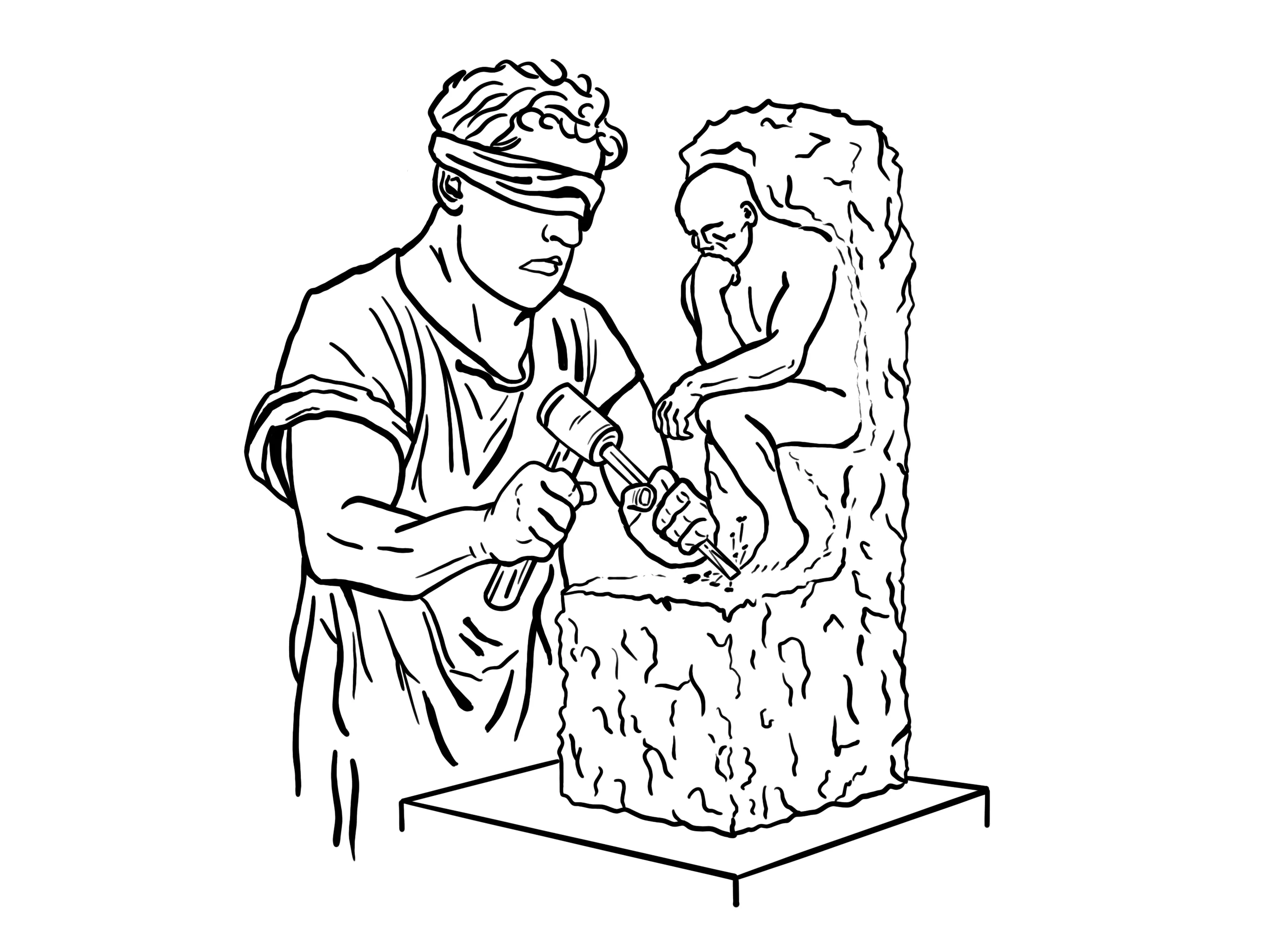
In the same way, a diffusion model trained on millions of images begins with random noise and iteratively transforms it into a clear image. Not by adding to a blank canvas, but by learning how to remove what does not belong.
That denoising process is the key idea behind modern AI image generation.
Let’s assume that we want to generate an image of a tree, and we start with a random unclear image.

What do you see? This is the starting point for the model: a canvas of pure random noise. To our eyes, it is a meaningless blurry blob. To the model, it is a field of possibility containing many faint candidate structures. At this stage, the model’s job is to decide which parts of the noise are least likely to belong in an image of a tree.

After several denoising steps, a faint structure begins to emerge. What do you see now? Perhaps a head of broccoli, an explosion, or a tree. It is still ambiguous, but a general shape is taking form. The model has peeled away the most obvious layers of noise, revealing a low-resolution silhouette. It is beginning to commit to a structure, but the details are still fluid. Can you identify which parts of the image still need to be cleaned up to see the tree better?

After many more refinement steps, the image becomes much clearer. It is almost certainly a tree. The main trunk and leafy canopy are now visible. The model has largely settled on the high-level concept. Its task is no longer to discover the overall structure, but to refine the details by carving out smaller branches and adding texture to the leaves. Can you identify the areas that need more refinement?

Finally, after hundreds of steps, we arrive at the final crisp image. We can clearly see the tree, complete with bark, leaf clusters, and a coherent overall structure. The model has removed the noise that was inconsistent with its goal. The journey from a noisy blob to a sharp final image is the essence of the diffusion process. This idea can feel counterintuitive at first. Human artists often create by adding marks to a blank surface, but diffusion models work in the opposite direction: they start with noise and iteratively remove what should not be there.
From toy denoiser to real image models
The tree example above is a visual story for the denoising idea. The toy simulation below uses tiny facial-expression grids instead, because they make the step-by-step refinement easier to inspect on a small screen. Real image generation systems use much larger neural networks, many more denoising steps, and text-conditioning mechanisms that connect the prompt to the image being refined. Many also rely on U-Net-style architectures to predict noise at each step. But the core mental model is the same: generation happens by repeatedly predicting what noise to remove next.
Start by choosing one of the target expressions and comparing the three panels: the clean target, the noisy input, and the denoised output. Then run the model and watch how the denoised panel gradually moves closer to the target while the loss changes over time. After that, experiment with the learning rate and noise beta. The learning rate affects how quickly the model updates, while beta controls how aggressively noise is injected into the input.
This toy is tiny, but it teaches the right habit of attention: image generation here is not a single jump from text to picture. It is an iterative refinement process. Watching those refinements step by step is the best way to build intuition for diffusion.
Clean target
Noisy input
Denoised output
Grokking AI Algorithms
How AI solves complex problems
A practical, visual guide to the algorithms that power search, machine learning, neural networks, LLMs, and generative AI.

Generative Image Models Frequently Asked Questions (FAQ)
What is a generative image model?
A generative image model is a system that creates new images rather than only classifying existing ones. It learns patterns of structure, texture, and composition from data and then uses that knowledge to synthesize new outputs.
What is diffusion in AI image generation?
Diffusion is a generative approach that starts from noise and learns how to reverse that noise step by step. The final result is an image that becomes more structured over time.
How does diffusion-based image generation work?
Diffusion models learn how to reverse noise step by step. Starting from a noisy image, they repeatedly denoise until recognizable structure appears.
What does denoising mean in AI image generation?
Denoising means predicting how to remove random corruption while preserving or recovering meaningful structure. In diffusion models, that repeated denoising process is the core mechanism behind image synthesis.
Why does image generation start from noise?
Noise provides a neutral starting point from which many different outputs can emerge. The model learns how to shape that randomness into coherent images.
What is a U-Net in diffusion models?
A U-Net is a neural network architecture commonly used to predict how an image should be denoised at each step. It is a key component in many modern diffusion pipelines.
What does conditioning mean in generative image models?
Conditioning means guiding generation with extra information, such as a text prompt, label, or partial image. It helps steer the model toward a desired kind of output.
Why are diffusion models popular for image generation?
They tend to produce high-quality results and offer a clear iterative generation process. Their denoising framework has also proven flexible for many image tasks.
Is this chapter demo a full production image generator?
No. It is a toy denoising system designed to teach the core intuition. The real systems used in modern tools are much larger and more sophisticated.
What does the chapter simulation help you understand?
It turns diffusion into something visual and approachable. You can watch noisy inputs become clearer and connect that process to the general idea behind modern image generation.
How does this chapter connect to text-to-image systems?
Text-to-image systems build on the same denoising intuition but add much larger models and text conditioning. This chapter gives you the conceptual bridge rather than the full production stack.