Artificial neural networks
Artificial neural networks (ANNs) are powerful tools in the machine learning toolkit, used in a variety of ways to accomplish objectives such as image recognition, natural language processing, and game playing. ANNs learn in a similar way to other machine learning algorithms: by using training data. They are best suited to unstructured data where it’s difficult to understand how features relate to one another. This chapter covers the inspiration of ANNs; it also shows how the algorithm works and how ANNs are designed to solve different problems.
Neural networks consist of interconnected neurons that pass information by using electrical and chemical signals. Neurons pass information to other neurons and adjust that information to accomplish a specific function. When you grab a cup and take a sip of water, millions of neurons process the intention of what you want to do, the physical action to accomplish it, and the feedback to determine whether you were successful. Think about little children learning to drink from a cup. They usually start out poorly, dropping the cup a lot. Then they learn to grab it with two hands. Gradually, they learn to grab the cup with a single hand and take a sip without any problems. This process takes months. What’s happening is that their brains and nervous systems are learning through practice or training. In our bodies, we have billions of neurons that are harnessed to learn from the signals of what we are doing, towards what goal, while determining our level of success.

Simplified, a neuron consists of dendrites that receive signals from other neurons; a cell body and a nucleus that activates and adjusts the signal; an axon that passes the signal to other neurons; and synapses that carry, and in the process adjust, the signal before it is passed to the next neuron’s dendrites. Through approximately 90 billion of these neurons working together, our brains can function at the high level of intelligence that we know.
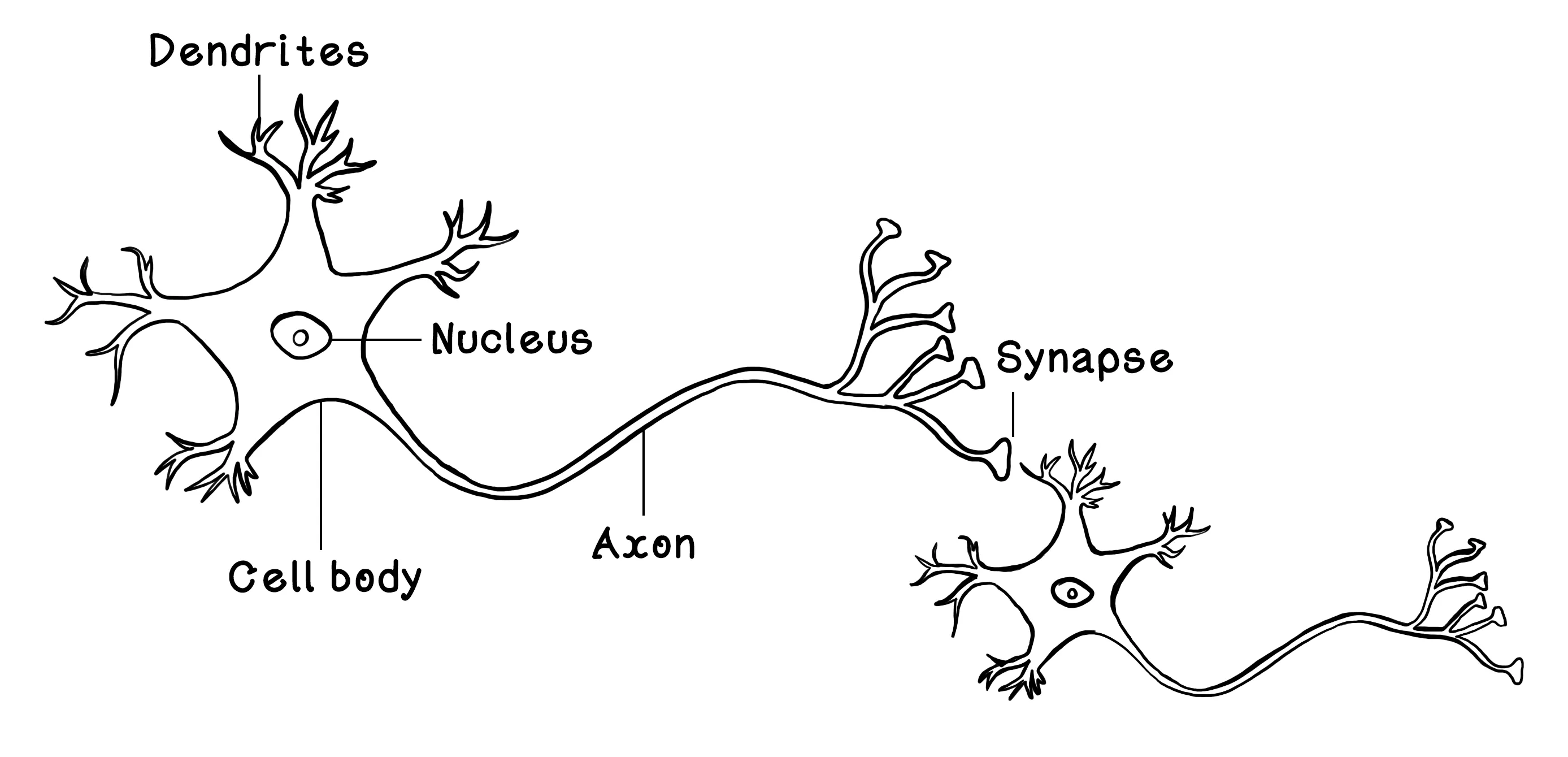
The neuron is the fundamental concept that makes up the brain. As mentioned earlier, it accepts many inputs from other neurons, processes those inputs, and transfers the result to other connected neurons. ANNs are based on the fundamental concept of the Perceptron — a logical representation of a single biological neuron. Like neurons, the Perceptron receives inputs (like dendrites), alters these inputs by using weights (like synapses), processes the weighted inputs (like the cell body and nucleus), and outputs a result (like axons). The Perceptron is loosely based on a neuron. You will notice that the synapses are depicted after the dendrites, representing the influence of synapses on incoming inputs.
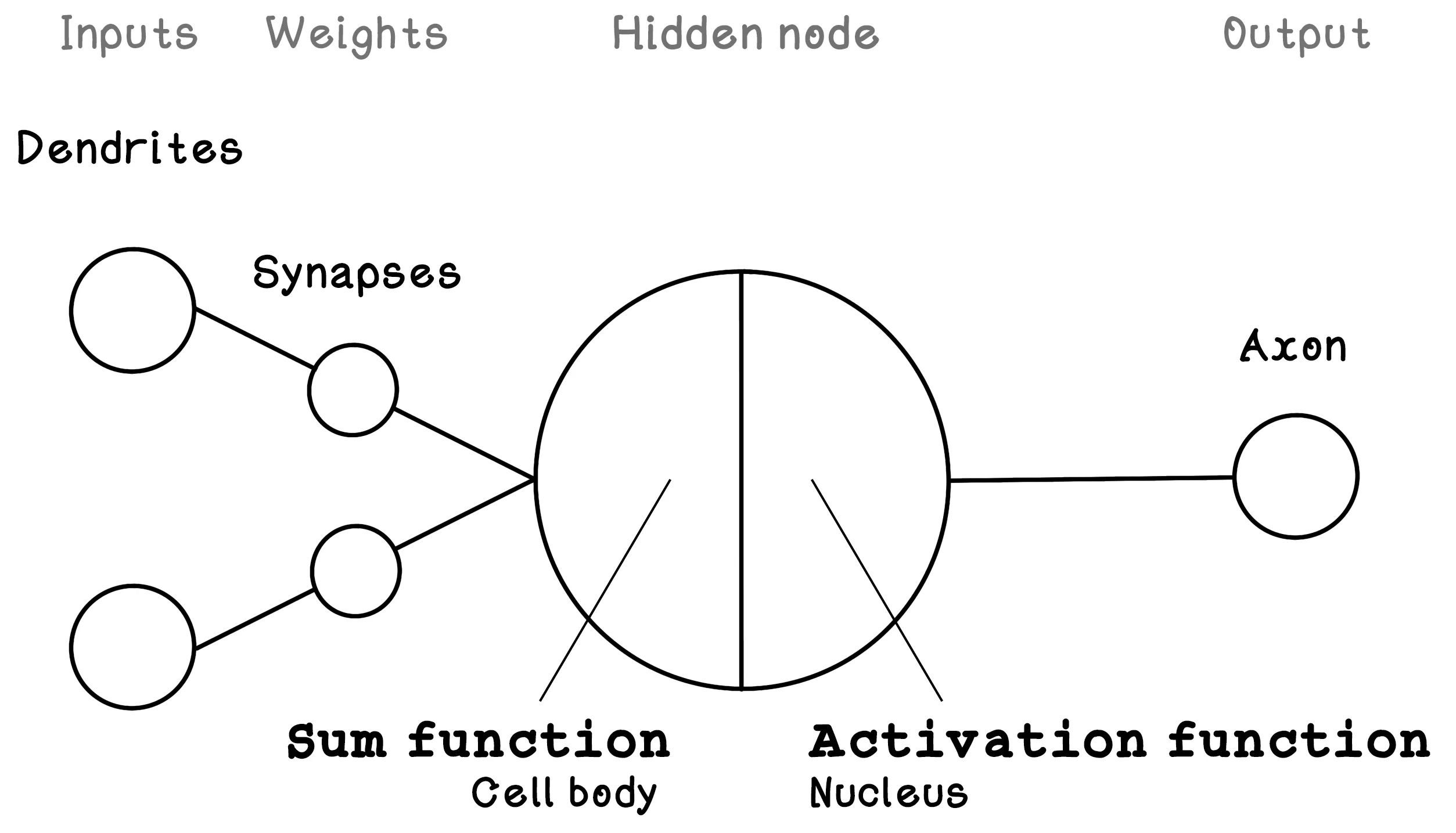
The components of the Perceptron are described by variables that are useful for calculating the output. Weights modify the inputs; that value is processed by a hidden node; and finally, the result is provided as the output. Here is a brief description of the components of the Perceptron:
- Inputs — Describe the input values. In a neuron, these values would be an input signal.
- Weights — Describe the weights on each connection between an input and the hidden node. Weights influence the intensity of an input and result in a weighted input. In a neuron, these connections would be the synapses.
- Hidden node (sum and activation) — Sums the weighted input values and then applies an activation function to the summed result. An activation function determines the activation/output of the hidden node/neuron.
- Output — Describes the final output of the Perceptron.
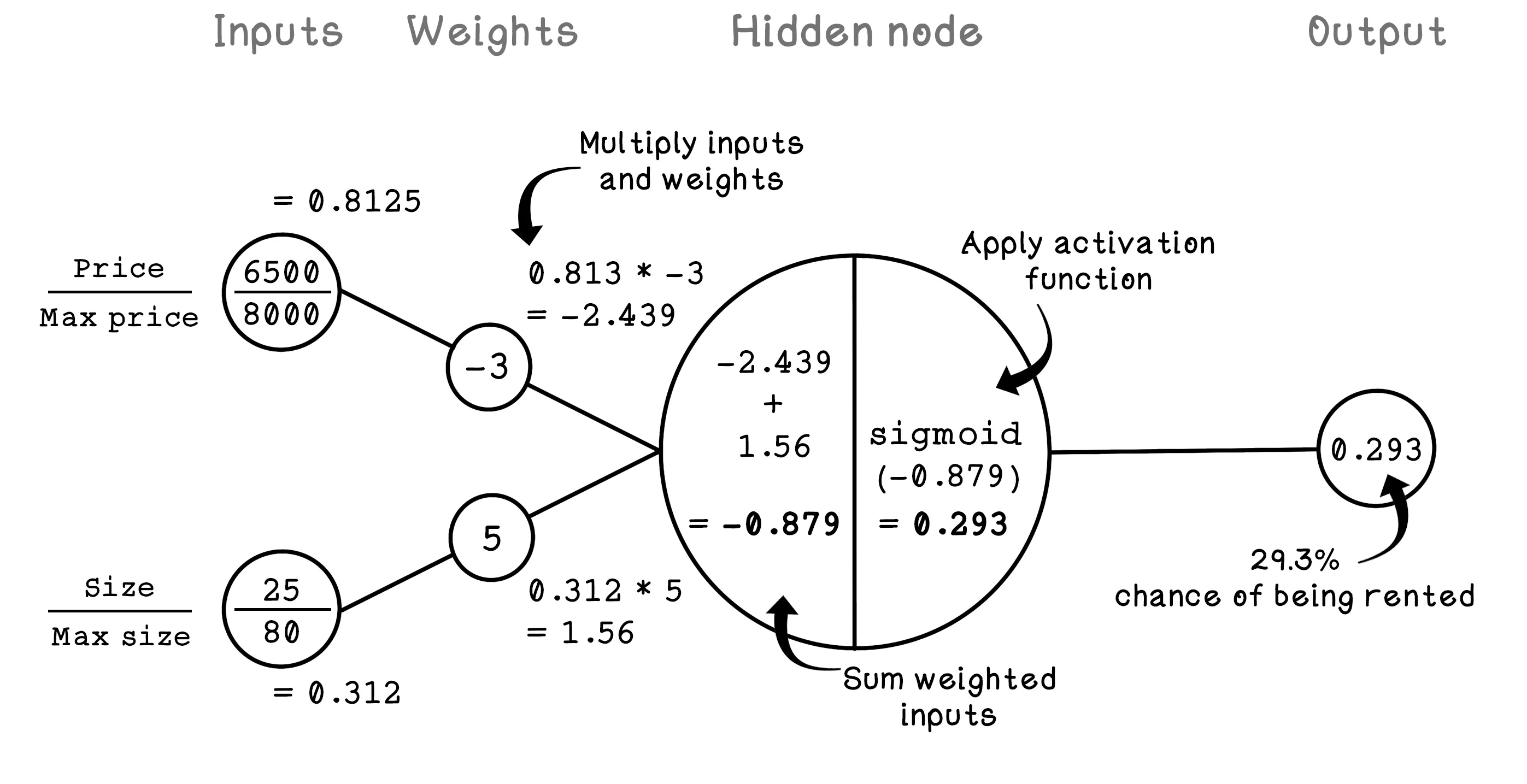
The Perceptron is useful for solving simple problems, but as the dimensions of the data increase, it becomes less feasible. ANNs use the principles of the Perceptron and apply them to many hidden nodes as opposed to a single one.
Why hidden layers matter
A single Perceptron is limited because it can only express simple relationships. Hidden layers let the network build intermediate representations that are more useful than the raw inputs alone. Instead of trying to jump directly from speed, terrain, vision, and experience to a yes-or-no answer, the network can learn internal concepts such as “risky conditions” or “high margin for error” and combine them into a final judgment.
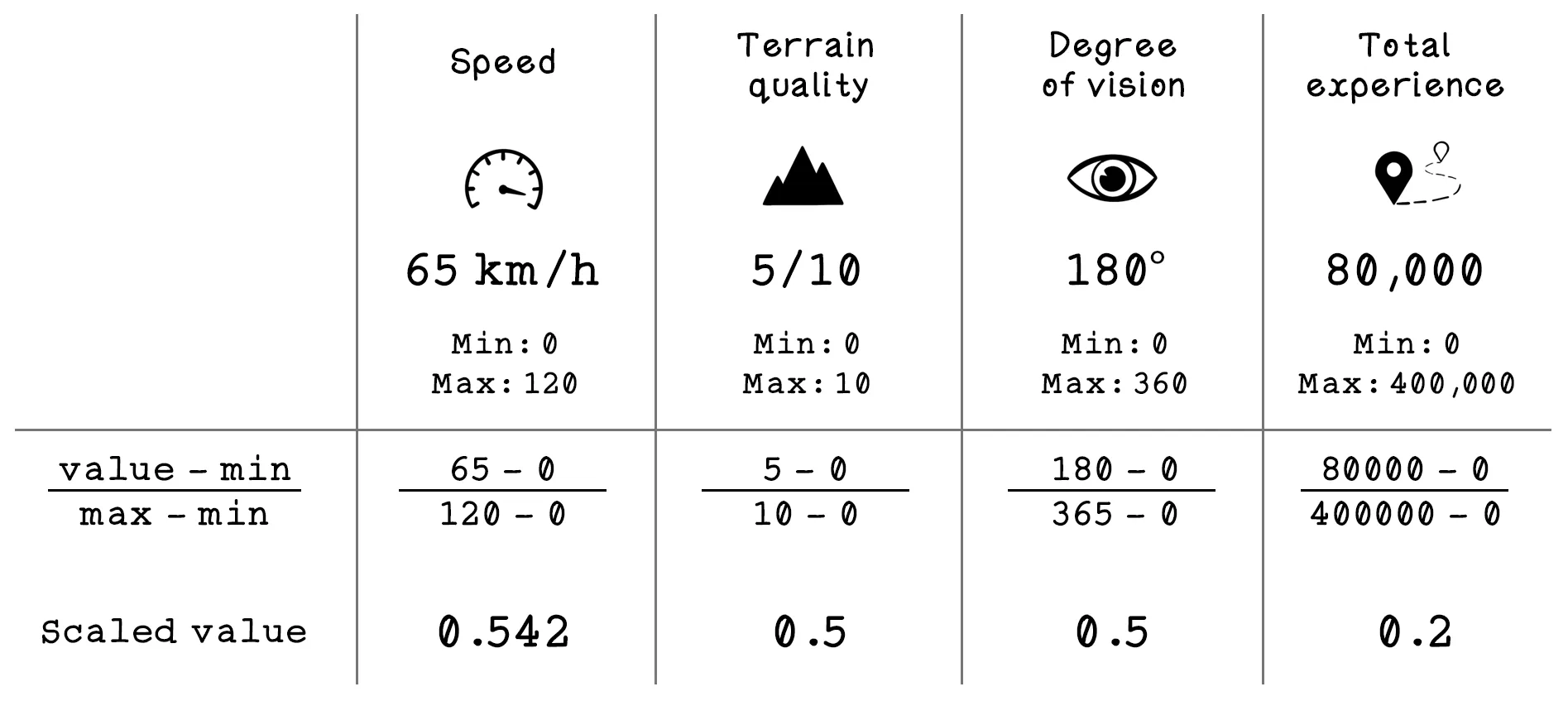
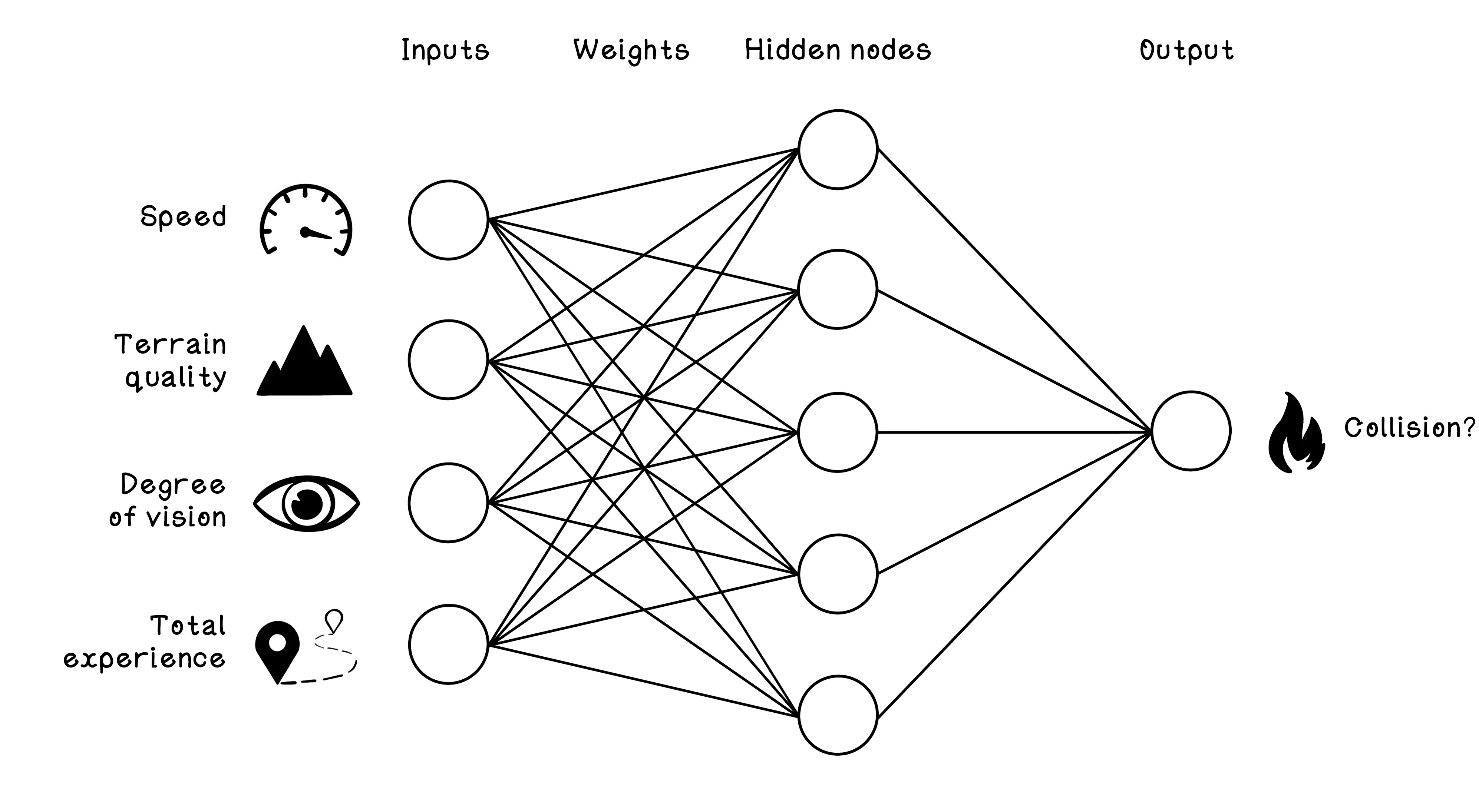
To explore the workings of multi-node ANNs, consider an example dataset related to car collisions. Suppose that we have data from several cars at the moment that an unforeseen object enters the path of their movement. The dataset contains features related to the conditions and whether a collision occurred, including the following:
- Speed — The speed at which the car was traveling before encountering the object
- Terrain quality — The quality of the road on which the car was traveling before encountering the object
- Degree of vision — The driver’s degree of vision before the car encountered the object
- Total experience — The total driving experience of the driver of the car
- Collision occurred? — Whether a collision occurred or not
| SPEED | TERRAIN | VISION | EXPERIENCE | LABEL |
|---|---|---|---|---|
| 75 mph | 2/10 | 148° | 180,626 mi | Accident |
| 93 mph | 2/10 | 69° | 288,001 mi | Accident |
| 126 mph | 10/10 | 166° | 274,291 mi | Accident |
| 8 mph | 7/10 | 212° | 184,746 mi | No accident |
| 62 mph | 6/10 | 110° | 330,085 mi | No accident |
| 116 mph | 10/10 | 50° | 179,895 mi | Accident |
An example ANN architecture can be used to classify whether a collision will occur based on the features we have. The features in the dataset must be mapped as inputs to the ANN, and the class that we are trying to predict is mapped as the output of the ANN. In this example, the input nodes are speed, terrain quality, degree of vision, and total experience; the output node is whether a collision happened.
How backpropagation helps the network learn
The network does not guess the right weights all at once. It starts with imperfect values, makes a prediction, compares that prediction with the correct label, and measures the error. Backpropagation is the process of sending that error signal backward through the network so each weight can be adjusted in the direction that reduces future error. In other words, backpropagation tells the model which connections helped and which connections hurt.
That matters because a neural network may contain many layers and many parameters. Without a systematic way to assign responsibility for error, training would be too slow and too vague. Backpropagation, combined with gradient descent, gives the network a practical recipe for learning from mistakes step by step.
The simulation below shows how the ANN can be used to classify whether a collision will occur based on the features we have. Start the model and watch the training loss and accuracy metrics first so you can see whether the network is actually learning. Then switch to the scenario game and compare your judgment with the model’s prediction. That sequence matters: first see the network improve through training, then test what it has learned on fresh situations.
This network is intentionally small enough to inspect. Real neural networks often have many more layers, parameters, and training examples, but they are still doing the same essential thing: transforming inputs into useful internal representations and improving those transformations through training.
Training loop
Binary classifier trained on simulated driving data.
New driving scenario
Decide if an accident will happen.
| Speed | — |
|---|---|
| Terrain quality | — |
| Vision | — |
| Total experience | — |
Grokking AI Algorithms
How AI solves complex problems
A practical, visual guide to the algorithms that power search, machine learning, neural networks, LLMs, and generative AI.

Artificial Neural Networks Frequently Asked Questions (FAQ)
What is a neural network?
A neural network is a model made of connected layers of weighted computations that transform inputs into outputs. It learns patterns by adjusting those weights during training.
What is a neuron in a neural network?
A neuron is a small computational unit that combines inputs, applies weights, adds them together, and then passes the result through an activation function. Many such units together create a network.
What do weights do in a neural network?
Weights control how strongly each input influences the next layer. Learning in a neural network mostly comes down to finding useful weight values.
What is an activation function?
An activation function transforms the weighted sum at a node into an output value. It helps the network model more complex behavior than a purely linear system could.
Why do hidden layers matter?
Hidden layers let the model learn intermediate patterns instead of relying on a single direct mapping from input to output. That makes neural networks much better at modeling more complex relationships than a single simple rule.
What is forward propagation?
Forward propagation is the process of sending input values through the network to produce a prediction. It is how the network uses its current weights to generate an output.
What is backpropagation?
Backpropagation is the process of pushing error information backward through the network so the weights can be updated. It is one of the key mechanisms that makes neural network training practical.
How does a neural network learn?
A neural network makes a prediction, measures how wrong it was, and then updates its weights to reduce that error. Repeating that process over many examples is what turns raw structure into learned behavior.
Why isn't a neural network just a bigger linear regression?
Because activation functions and hidden layers allow it to model nonlinear relationships. That extra flexibility is why neural networks can represent much richer patterns.
What does the chapter simulation help you see?
It shows how inputs, hidden units, outputs, loss, and accuracy relate during training. That visual feedback makes the network's learning process less opaque.
When should someone learn neural networks after linear regression?
Right after they understand the basic learning loop. Neural networks are easier to grasp once concepts like parameters, prediction error, and training updates already feel familiar.